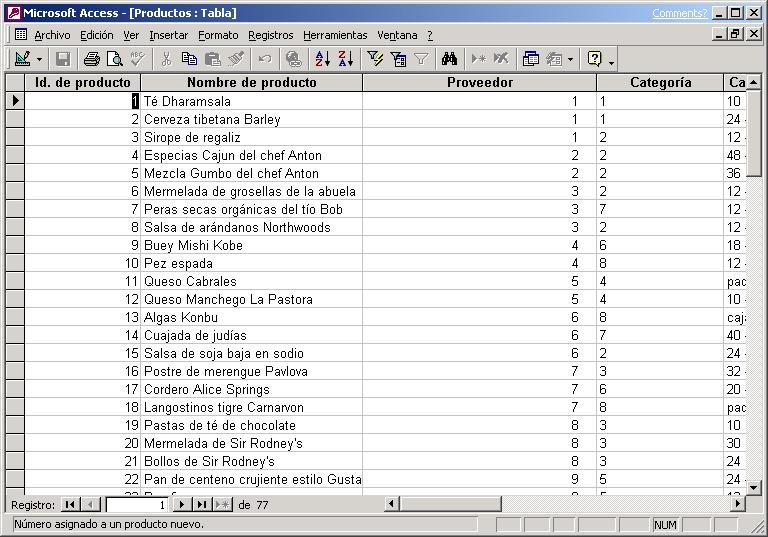
Es un sistema de gestión de bases de datos relacionales para los sistemas operativos Microsoft Windows, desarrollado por Microsoft y orientado a ser usado en un entorno personal o en pequeñas organizaciones. Es un componente de la suite ofimática Microsoft Office. Permite crear ficheros de bases de datos relacionales que pueden ser fácilmente gestionadas por una interfaz gráfica simple. Además, estas bases de datos pueden ser consultadas por otros programas. Este programa permite manipular los datos en forma de tablas (formadas por filas y columnas), crear relaciones entre tablas, consultas, formularios para introducir datos e informes para presentar la información.
Microsoft Access posee varias versiones desde su creación en 1992; a continuación se expone de forma detallada cada una de ellas:
Versión Número de versión Fecha de publicación Jet version Sistema operativo compatible Versión de la suite de Office
Access 1.1 1 1992 1.1 Windows 3.0
Access 2.0 2.0 1993 2.0 Windows 3.1x Office 4.3 Pro
Access para Windows 95 7.0 24 Ago., 1995 3.0 Windows 95 Office 95 Professional
Access 97 8.0 16 Ene., 1997 3.5 Windows 9x, NT 3.51/4.0 Office 97 Professional and Developer
Access 2000 9.0 7 Jun., 1999 4.0 SP1 Windows 9x, NT 4.0, 2000, XP Office 2000 Professional, Premium and Developer
Access 2002 10 31 May., 2001 4.0 SP1 Windows 98, Me, 2000, XP Office XP Professional and Developer
Access 2003 11 27 Nov. , 2003 4.0 SP1 Windows 2000, XP, XP Professional x64, Vista Office 2003 Professional and Professional Enterprise
Access 2007 12 27 Ene. , 2007 12 Windows XP SP2, XP Professional x64, Vista, Windows 7 Office 2007 Professional, Professional Plus, Ultimate and Enterprise
Access 2010 14 15 Jul., 2010 14 Windows XP SP3, Vista, Windows 7 Office 2010 Professional, Professional Academic and Professional Plus
Microsoft Access posee varias versiones desde su creación en 1992; a continuación se expone de forma detallada cada una de ellas:
Versión Número de versión Fecha de publicación Jet version Sistema operativo compatible Versión de la suite de Office
Access 1.1 1 1992 1.1 Windows 3.0
Access 2.0 2.0 1993 2.0 Windows 3.1x Office 4.3 Pro
Access para Windows 95 7.0 24 Ago., 1995 3.0 Windows 95 Office 95 Professional
Access 97 8.0 16 Ene., 1997 3.5 Windows 9x, NT 3.51/4.0 Office 97 Professional and Developer
Access 2000 9.0 7 Jun., 1999 4.0 SP1 Windows 9x, NT 4.0, 2000, XP Office 2000 Professional, Premium and Developer
Access 2002 10 31 May., 2001 4.0 SP1 Windows 98, Me, 2000, XP Office XP Professional and Developer
Access 2003 11 27 Nov. , 2003 4.0 SP1 Windows 2000, XP, XP Professional x64, Vista Office 2003 Professional and Professional Enterprise
Access 2007 12 27 Ene. , 2007 12 Windows XP SP2, XP Professional x64, Vista, Windows 7 Office 2007 Professional, Professional Plus, Ultimate and Enterprise
Access 2010 14 15 Jul., 2010 14 Windows XP SP3, Vista, Windows 7 Office 2010 Professional, Professional Academic and Professional Plus














 El reporte puede ser la conclusión de una investigación previa o adoptar una
El reporte puede ser la conclusión de una investigación previa o adoptar una